Storage Blob Data Contributor role. For more information, read User assigned with the Storage Blob Data Contributor role.
Properties
Reference material is provided below for the Connect, Configure, Destination, and Advanced Settings properties.A human-readable name for the component.
Connect
Your Workday host name. Read Workday authentication guide to learn how to acquire this credential.
Your Workday Tenant ID. Read Workday authentication guide to learn how to acquire this credential.
The authentication method to authorize access to your Workday data. Choose OAuth 2.0 Authorization Code to use an OAuth connection, or Username & password to use a username and password.
(OAuth 2.0 Authorization Code only)Choose your OAuth connection from the drop-down menu.Click Manage to navigate to the OAuth connections list to review OAuth connections and to add new connections. Read OAuth to learn how to create an OAuth connection.Additionally, read Workday authentication guide, which explains how to create an OAuth connection for Workday.
(Username & password only) Your Workday username.
(Username & password only)Choose the secret definition that represents your credentials for this connector.If you have not already saved your credentials for this connector as a secret definition, click Add secret to create a secret definition representing these credentials. Read Secrets and secret definitions for details about creating a secret definition.
- Parameter: A JDBC parameter supported by the database driver. The available parameters are explained in the data model. Manual setup is not usually required, since sensible defaults are assumed.
- Value: A value for the given parameter.
Configure
- Full Load: Select this option to load your entire dataset.
- Incremental Load: Select this option to only load new and updated records from your dataset.
- Basic: This mode will build a query for you using settings from the Schema, Data Source, Data Selection, Data Source Filter, Combine Filters, and Limit parameters. In most cases, this mode will be sufficient.
- Advanced: This mode will require you to write an SQL-like query to call data from the service you’re connecting to. The available fields and their descriptions are documented in the data model.
Advanced mode is currently not supported when Incremental Load is selected.
While the query is exposed in an SQL-like language, the exact semantics can be surprising, for example, filtering on a column can return more data than not filtering on it. This is an impossible scenario with regular SQL.
- SOAP: Select this option to execute a SOAP operation to return three columns (Response, FaultCode, and FaultString). When this option is selected, the Request XML property appears.
- SQL: Select this option to write an SQL-like SELECT query to collect data. When this option is selected, the SQL Query property appears.
This is an SQL-like SELECT query. Treat collections as table names, and fields as columns. Only available in Advanced mode.For more information, read the Snowflake SELECT documentation.Only available when Advanced Mode Type is SQL.
In Basic mode, select the Workday service you want to query. The drop-down will include all available services.
In Advanced mode, enter the name of the Workday service you want to query.
Enter an XML query to collect data. Only available when Advanced Mode Type is SOAP.
Select a single data source to be extracted from the source system and loaded into a table in the destination. The source system defines the data sources available. Use multiple components to load multiple data sources.
Choose one or more columns to return from the query. The columns available are dependent upon the data source selected. Move columns left-to-right to include in the query.To use grid variables, select the Use Grid Variable checkbox at the top of the Data Selection dialog.
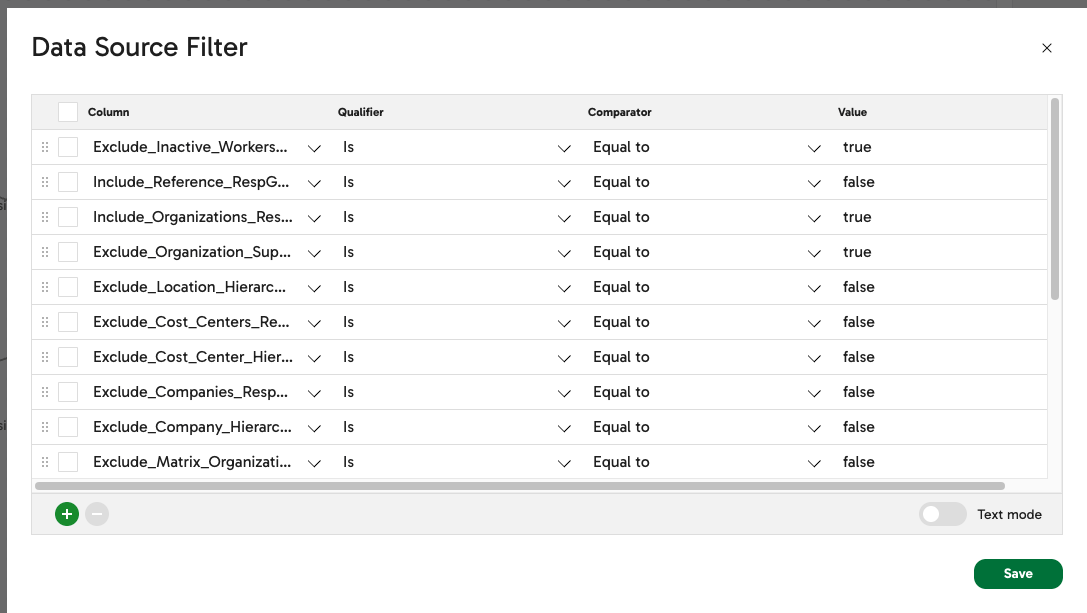
Define one or more filter conditions that each row of data must meet to be included in the load.
- Input Column: Select an input column. The available input columns vary depending upon the data source.
- Qualifier:
- Is: Compares the column to the value using the comparator.
- Not: Reverses the effect of the comparison, so “Equals” becomes “Not equals”, “Less than” becomes “Greater than or equal to”, etc.
- Comparator: Choose a method of comparing the column to the value. Possible comparators include: “Equal to”, “Greater than”, “Less than”, “Greater than or equal to”, “Less than or equal to”, “Like”, “Null”. Not all data sources support all comparators.
- Value: The value to be compared.
The data source filters you have defined can be combined using either And or Or logic. If And, then all filter conditions must be satisfied to load the data row. If Or, then only a single filter condition must be satisfied. The default is And.If you have only one filter, or no filters, this parameter is essentially ignored.
Set a numeric value to limit the number of rows that are loaded. The default is an empty field, which will load all rows.
When Incremental Load is selected, select a datetime field from your dataset that is always updated when your data changes, such as
dateModified. The connector will record the maximum value of this field each time you run this pipeline. On subsequent runs when Incremental Load is selected, only data with a higher value in this field will be loaded.If no rows in the source have a higher value than the stored high-water mark, the task will complete with a “task is skipped” message. This is expected behavior, indicating that no new or updated data was found since the last successful run.
Destination
- Snowflake
- Google BigQuery
Select the destination for your data. This is either in Snowflake as a table or as files in cloud storage.
- Snowflake: Load your data into a table in Snowflake. The data must first be staged via Snowflake or a cloud storage solution.
- Cloud Storage: Load your data directly into files in your preferred cloud storage location. The format of these files can differ between source systems and will not have a file extension so we suggest inspecting the output to determine the format of the data.
When Incremental Load is selected, Cloud Storage is not supported as a destination. Only warehouse destinations (Snowflake or Google BigQuery) are available for incremental loads.
- Snowflake
- Cloud Storage
The Snowflake warehouse used to run the queries. The special value
[Environment Default] uses the warehouse defined in the environment. Read Overview of Warehouses to learn more.The Snowflake database to access. The special value
[Environment Default] uses the database defined in the environment. Read Databases, Tables and Views - Overview to learn more.The Snowflake schema. The special value
[Environment Default] uses the schema defined in the environment. Read Database, Schema, and Share DDL to learn more.The name of the table to be created in your Snowflake database. You can use a Table Input component in a transformation pipeline to access and transform this data after it has been loaded.
Define what happens if the table name already exists in the specified Snowflake database and schema. Only available when Full Load is selected.
- Replace: If the specified table name already exists, that table will be destroyed and replaced by the table created during this pipeline run.
- Truncate and Insert: Each time the pipeline runs, two operations are performed: first, the table is truncated, meaning all existing rows are deleted. Then, your new rows are inserted. The table itself is never destroyed and recreated.
- Fail if Exists: If the specified table name already exists, this pipeline will fail to run.
- Append: If the specified table name already exists, then the data is inserted without altering or deleting the existing data in the table. It’s appended onto the end of the existing data in the table. If the specified table name doesn’t exist, then the table will be created, and your data will be inserted into the table.
Choose one or more columns to be designated as the table’s primary key.When using Incremental Load, if you select a primary key, the loaded data will be merged with your existing data. If you don’t select a primary key, the loaded data will be appended to your existing data.
- Yes: Staged files will be destroyed after data is loaded. This is the default setting.
- No: Staged files are retained in the staging area after data is loaded.
Select the stage access strategy. The strategies available depend on the cloud platform you select in Stage Platform.
- Credentials: Connects to the external stage (AWS, Azure) using your configured cloud provider credentials. Not available for Google Cloud Storage.
- Storage Integration: Use a Snowflake storage integration to grant access to Snowflake to read data from and write to a cloud storage location. This will reveal the Storage Integration property, through which you can select any of your existing Snowflake storage integrations.
Use the drop-down menu to choose where the data is staged before being loaded into your Snowflake table.
- Amazon S3: Stage your data on an AWS S3 bucket.
- Snowflake: Stage your data on a Snowflake internal stage.
- Azure Storage: Stage your data in an Azure Blob Storage container.
- Google Cloud Storage: Stage your data in a Google Cloud Storage bucket.
Select the Snowflake internal stage type. Use the Snowflake links provided to learn more about each type of stage.
- User: Each Snowflake user has a user stage allocated to them by default for file storage. You may find the user stage convenient if your files will only be accessed by a single user, but need to be copied into multiple tables.
- Named: A named stage provides high flexibility for data loading. Users with the appropriate privileges on the stage can load data into any table. Furthermore, because the stage is a database object, any security or access rules that apply to all objects will apply to the named stage.
Select your named stage. Read Creating a named stage to learn how to create a new named stage.
Advanced Settings
Set the file format used to stage extracted records from this component before loading. The default is
CSV. CSV is compact and widely compatible, while JSON Lines preserves the difference between NULL and empty-string values.Choose how to change the column names in your data so that they conform to the destination warehouse’s identifier rules:
None: (Default) Do not change the source column names.Alphanumeric (lower case): Replace non-alphanumeric characters with underscores, change the name to lowercase, and add an underscore at the start of the name if it begins with a digit.Alphanumeric (upper case): Replace non-alphanumeric characters with underscores, change the name to uppercase, and add an underscore at the start of the name if it begins with a digit.
Choose whether to automatically log debug information about your load. These logs can be found in the task history and should be included in support requests concerning the component. This property is set to No by default. Turning this on will override any debugging Connection Options you may have set.
The level of detail you want to include in your debug logs. Select a level between 1 and 4:
- Will log the query, the number of rows returned by it, the start of execution, the time taken, and any errors.
- Will log everything included in Level 1, plus cache queries and additional information about the request, if applicable.
- Will log everything included in Levels 1 and 2, and additionally log the body of the request and the response. This is the default logging level when debug logging is activated.
- Will log everything included in Levels 1, 2, and 3, and additionally log transport-level communication with the data source. This includes SSL negotiation.
Converts common strings that represent null into a null value. This is case-sensitive and works with the following strings: "", “NULL”, “NUL”, “Null”, “null”. The default is No.
Currently, this property is only applicable when using Snowflake as your destination.
When Yes, remove leading and trailing characters from a string column. The default is No.
Data model
The JDBC driver for this component models Workday services as separate schemas. You can find the default list of services here. This connector also allows you to query system tables in Advanced mode. To see the available system tables in the data model, read the System Tables section of the data model. For more information about using system tables, read our System tables guide.Data source filtering using prompts
You can use prompts when configuring the Data Source Filter property for the Workday Load connector in order to define the filter criteria by passing a specific XML block as a string. The steps to do this depend on whether you are using Advanced or Basic mode to configure the connector. For more information, read Prompts.Advanced mode
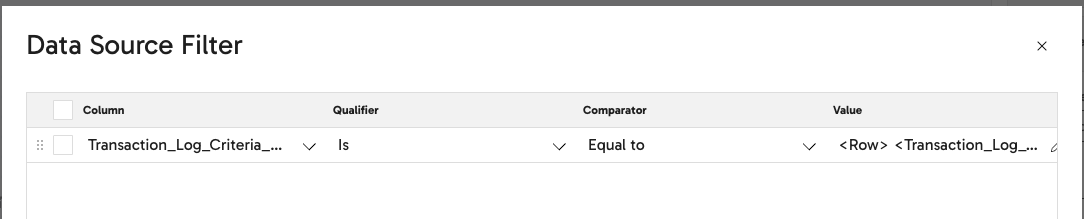
In Advanced mode, include the filter criteria in your SQL query. For example, to filter theTransaction_Log_Criteria_Data column by Updated_From, Updated_Through, Effective_From, and Effective_Through on the Workers endpoint in the Human_Resources service:
Basic mode
In Basic mode, configure the Data Source Filter property as follows:- Column: Enter your column name, e.g.
Transaction_Log_Criteria_Data - Qualifier:
Is - Comparator:
Equal to - Value: Enter the prompt value, without the initial
SELECTstatement. In the example above, this would be everything except the first line.
Workers_Worker_Organisation_Data data source, add the additional response groups in the Data Source Filter configuration. For example, Exclude_Location_Hierarchies_RespGroup set to false would include location hierarchy data in the response: